文本¶
文本操作
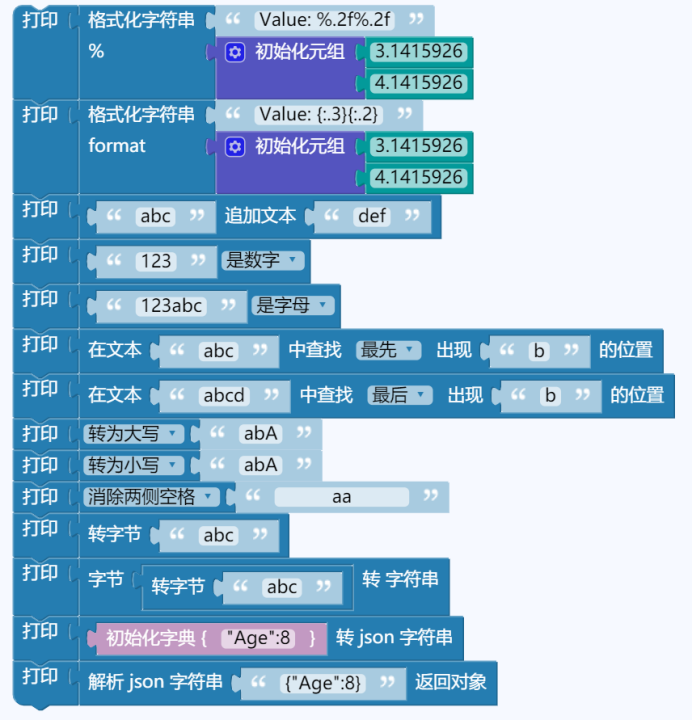
str.isdigit()¶
描述: 检测字符串是否只由数字组成
str.isalpha()¶
描述: 检测字符串是否只由字母组成
str.find(str, beg=0, end=len(string))¶
描述: 检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,如果指定范围内如果包含指定索引值,返回的是索引值在字符串中的起始位置。如果不包含索引值,返回-1
返回值: 如果包含子字符串返回开始的索引值,否则返回-1
参数:
str- 指定检索的字符串
beg- 开始索引,默认为0
end- 结束索引,默认为字符串的长度
str.rfind(str, beg=0 end=len(string))¶
描述: 返回字符串最后一次出现的位置,如果没有匹配项则返回-1
返回值: 返回字符串最后一次出现的位置,如果没有匹配项则返回-1
参数:
str- 指定检索的字符串
beg- 开始索引,默认为0
end- 结束索引,默认为字符串的长度
str.strip([chars])¶
描述: 移除字符串头尾指定的字符(默认为空格)或字符序列
返回值: 返回移除字符串头尾指定的字符序列生成的新字符串
参数:
chars- 移除字符串头尾指定的字符序列
bytes([source[, encoding[, errors]]])¶
描述: 返回一个新的 bytes 对象,该对象是一个 0 <= x < 256 区间内的整数不可变序列。它是 bytearray 的不可变版本
返回值: 返回一个新的 bytes 对象
参数:
source- 如果 source 为整数,则返回一个长度为 source 的初始化数组
source- 如果 source 为字符串,则按照指定的 encoding 将字符串转换为字节序列
source- 如果 source 为可迭代类型,则元素必须为[0 ,255] 中的整数
source- 如果 source 为与 buffer 接口一致的对象,则此对象也可以被用于初始化 bytearray
source- 如果没有输入任何参数,默认就是初始化数组为0个元素
bytes.decode(encoding="utf-8", errors="strict")¶
描述: 以指定的编码格式解码 bytes 对象。默认编码为 'utf-8'
返回值: 返回解码后的字符串
参数:
encoding- 要使用的编码,如"UTF-8"
errors- 设置不同错误的处理方案。默认为 'strict',意为编码错误引起一个UnicodeError。 其他可能得值有 'ignore', 'replace', 'xmlcharrefreplace', 'backslashreplace' 以及通过 codecs.register_error() 注册的任何值
ujson.dumps(obj)¶
描述: 将 dict 类型的数据转换成 str,因为如果直接将 dict 类型的数据写入 json 文件中会发生报错,因此在将数据写入时需要用到该函数
返回值: 返回转换后的 json 字符串
参数:
obj- 要转换的对象